
前面学习到单链表,发现有一个问题,如果我们想要remove一个节点,时间复杂度将会是O(n),并不理想。循环双链表和单链表相比,可以将一些操作,比如remove的时间复杂度降到O(1)。
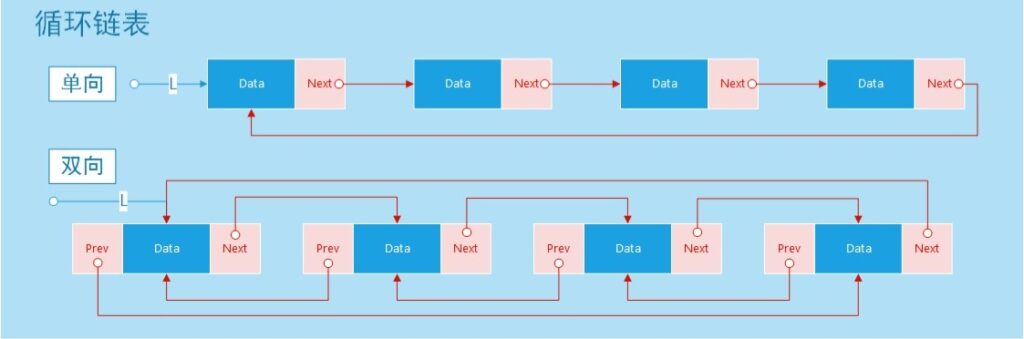
循环双向链表的结构单链表的节点具有两个元素:
- Data
- Next
双向链表在此基础上,增加了一个Prev(前节点)元素,具有三个元素:
- Prev
- Data
- Next
链表的末尾端和起始端相连,形成一个环状结构, 如下图所示:
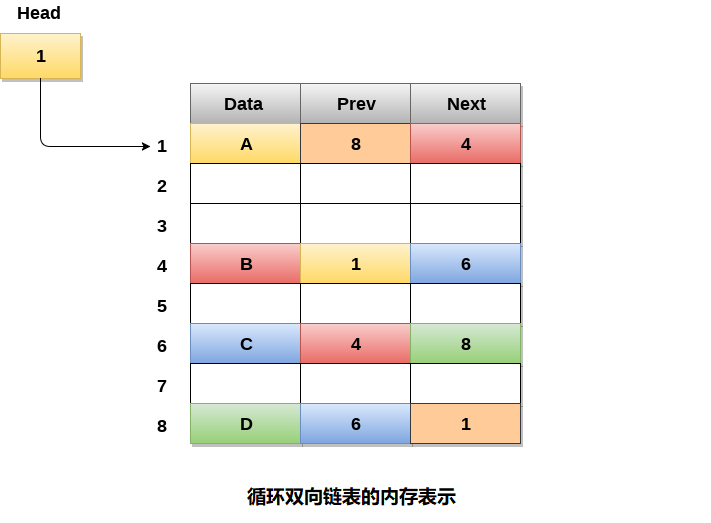
循环双向链表的内存管理
下图显示了为循环双向链表分配内存的方式。 变量head包含链表的第一个元素的地址,即地址1,因此链表的起始节点包含数据A存储在地址1中。因此,链表的每个节点应该具有三个部分,起始节点包含最后一个(也是前一个)节点的地址,即8和下一个节点,即4。链表的最后一个节点,存储在地址8并包含数据6,包含链表的第一个节点的地址,如图中所示,即地址1。在循环双向链表中,最后一个节点由第一个节点的地址标识,该节点存储在最后一个节点的next中,因此包含第一个节点地址的节点实际上是该节点的最后一个节点。
循环双向链表在Python中的实现:
#定义节点 class Node(object): def __init__(self,value=None,next=None,prev=None): self.value,self.next,self.prev=value,next,prev #注意和单链表相比,多出了一个prev #定义循环双向链表 class CircularDoubleLinkedList(object): #默认需要有maxsize,length,prev,next和root def __init__(self,maxsize=None): self.maxsize=maxsize self.length=0 node=Node() self.prev=node #初始设置是一个闭环,根节点,头节点,尾节点都设置为空节点 self.next=node self.root=node #定义长度 def __len__(self): return self.length #定义头节点 def headnode(self): return self.root.next #定义头节点和尾节点后面会比较方便 #定义尾节点,是根节点的前一个节点,因为是循环链表 def tailnode(self): return self.root.prev #链表末端追加一个元素 def append(self,value): if self.maxsize is not None and len(self)>self.maxsize: raise Exception("Full") tailnode=self.tailnode() or self.root #如果链表为空的话,取根节点,否则取尾节点 node=Node(value) #新建一个节点 tailnode.next=node #尾节点后面加上新的节点 node.prev=tailnode #新点前面连上尾节点 node.next=self.root #新节点后面连上根节点,从而形成一个循环 self.root.prev=node #根节点从前面连上新节点 self.length+=1 #长度增加1 #链表起始端追加一个元素 def appendleft(self,value): if self.maxsize is not None and len(self)>self.maxsize: raise Exception("Full") #防止超过最大容量 node=Node(value) if self.root.next == self.root: #如果链表为空,是个闭环,只有根节点 self.root.next=node #根节点后面要插入新的节点 self.root.prev=node #根节点前面面也是新的节点 node.prev=self.root node.next=self.root #新节点前后都是根节点 self.tailnode=node #尾节点要更新成新节点 else: headnode=self.headnode() #如果链表不为为空,先读取头节点 self.root.next=node #根节点后插入新节点 node.next=headnode #新节点后面连上头节点 headnode.prev=node #头节点前面是新节点 node.prev=self.root #新节点前面是根节点 self.length+=1 #长度增加1 #删除一个元素 def remove(self,node): #O(1) if node is self.root: #注意这个方法是输入node,并且输出node return else: node.prev.next=node.next #跳过要删除的节点,把前后节点连起来 node.next.prev=node.prev self.length-=1 return node #这个方法的时间复杂度不再是O(n),而是O(1) #遍历,返回节点 def iter_node(self): if self.root.next == self.root: #如果是空链表,直接返回 return currnode=self.root.next while currnode.next is not self.root: #从头节点开始,一直循环到当前节点的下一个节点如果是尾节点,就停止了 yield currnode currnode=currnode.next yield currnode #注意最后一个节点并没有生成出来,最后要补上 #遍历,返回节点的值 def __iter__(self): for node in self.iter_node(): #取节点的值 yield node.value #反向遍历 def iter_node_reverse(self): #和上面大同小异,惟一的区别是,检查完一个节点后,往前走,用prev,而不是next if self.root.prev == self.root: return currnode=self.root.prev while currnode.prev is not self.root: yield currnode currnode=currnode.prev yield currnode #插入新节点 def insert(self,value,new_value): for node in self.iter_node(): if node.value==value: #如果找到值 new_node=Node(new_value) #建立一个新节点 if node.next is not self.root: #如果要找的节点不是尾节点 nextnode=node.next #先读取下一个节点 node.next=new_node #把当前节点的下一个节点替换为新节点 new_node.prev=node #新节点前面连上当前节点 new_node.next=nextnode #新节点的后面连上原本的下一个节点 nextnode.prev=new_node #原本的下一个节点前面要连上新节点 else: node.next=new_node #如果要找的节点是尾节点,当前节点后面要连上新节点 new_node.prev=node # 新节点前面连上当前节点 new_node.next=self.root # 新节点后面没有节点了,需要回到根节点 self.root.prev=new_node #根节点前面是新节点 self.length+=1 return 1 return -1 #整个链表都没找到值的话需要返回-1 #测试 def test_double_link_list(): dll = CircularDoubleLinkedList() assert len(dll) == 0 dll.append(0) dll.append(1) dll.append(2) assert list(dll) == [0, 1, 2] assert [node.value for node in dll.iter_node()] == [0, 1, 2] assert [node.value for node in dll.iter_node_reverse()] == [2, 1, 0] headnode = dll.headnode() assert headnode.value == 0 dll.remove(headnode) assert len(dll) == 2 assert [node.value for node in dll.iter_node()] == [1, 2] dll.appendleft(0) assert [node.value for node in dll.iter_node()] == [0, 1, 2] dll.insert(2,3) assert [node.value for node in dll.iter_node()] == [0, 1, 2, 3] if __name__ == '__main__': test_double_link_list()